Korpus dalam Penyusunan Kamus

Pendahuluan
Kamus merupakan deskripsi kosakata dari suatu bahasa. Kamus menjelaskan apa arti kata dan menunjukkan bagaimana kata itu bekerja sama untuk membentuk kalimat. Informasi yang disajikan dalam kamus itu diperoleh dari dua sumber utama, yaitu introspeksi dan observasi. Introspeksi berarti melihat ke dalam otak kita sendiri dan mencoba mengingat semua yang kita tahu tentang kata. Sementara itu, observasi berarti memeriksa contoh-contoh nyata dari bahasa yang digunakan (dalam surat kabar, novel, blog, twit, dsb.) sehingga kita dapat mengamati bagaimana orang menggunakan kata-kata ketika mereka berkomunikasi satu sama lain.
Penutur yang fasih dalam suatu bahasa tentunya harus sudah tahu banyak tentang kosakata bahasa itu. Oleh karena itu, introspeksi dapat menjadi sumber wawasan yang berguna tentang apa makna kata itu dan bagaimana kata itu digunakan. Akan tetapi, kamus harus memberikan laporan lengkap dan seimbang mengenai perilaku sebuah kata, dan introspeksi saja tidak dapat memberikan informasi yang cukup untuk tujuan itu. Akibatnya, para pekamus, sejak zaman Samuel Johnson pada abad ke-18, telah memilih untuk mendasarkan kamus mereka pada observasi. Di era Johnson, mengamati bahasa adalah pekerjaan yang melelahkan. Mengamati bahasa sama dengan membaca ratusan buku dan penggalian contoh yang baik dari kata-kata yang digunakan. Namun, teknologi komputer saat ini membuat semua itu lebih mudah. Teknologi komputer memberi kita akses ke begitu banyak data bahasa yang baik sehingga kita sekarang mampu memberikan penjelasan yang benar-benar dapat diandalkan tentang kosakata suatu bahasa (Macmillan Dictionaries: 2014).
Tulisan ini akan memaparkan peran korpus dalam penyusunan kamus. Untuk itu, terlebih dahulu akan dipaparkan pengertian tentang korpus, sejarah ringkas korpus, dan tipologi korpus. Kemudian akan dilanjutkan dengan kamus dan peran korpus dalam penyusunan kamus.
Observasi bahasa: pengutipan dan korpus
Para pekamus telah menggunakan pengutipan (citation) sudah sejak lama. Contoh kata-kata contoh kata-kata yang digunakan diambil dari buku atau sumber lain sebagai dasar untuk menggambarkan suatu bahasa. Data yang diperoleh dengan cara pengutipan itu sangat berguna untuk melacak perubahan dalam bahasa serta untuk mengenali kata-kata dan frasa baru ketika muncul dalam penggunaan. Hingga saat ini, pengutipan masih berperan dalam penyusunan kamus.
Sementara itu, penggunaan korpus dalam penyusunan kamus dewasa ini telah menjadi tren. Korpus adalah kumpulan teks alami, baik bahasa lisan maupun bahasa tulis, yang disusun secara sistematis. Dikatakan “alami” karena teks yang dikumpulkan merupakan teks yang diproduksi dan digunakan secara wajar dan tidak dibuat-buat. Teks-teks tersebut termasuk novel, buku dan kertas akademis, koran, majalah, rekaman siaran pembicaraan dan wawancara, blog, jurnal daring, dan kelompok diskusi, dan banyak lagi. Dikatakan “sistematis” karena struktur dan isi korpus mengikuti prinsip ekstralinguistik tertentu, khususnya prinsip pengambilan sampel, yaitu prinsip dasar dalam pemilihan teks yang akan dimasukkan ke dalam korpus. Misalnya, ada korpus yang dibatasi pada jenis teks tertentu, untuk satu atau beberapa variasi bahasa Inggris, atau untuk jangka waktu tertentu. “Sistematis” juga berarti bahwa informasi tentang komposisi yang tepat dari suatu korpus tersedia bagi peneliti (termasuk jumlah kata dalam setiap kategori dan keseluruhan korpus, bagaimana teks-teks yang termasuk dalam korpus dijadikan sampel, dsb.). Meskipun korpus dapat merujuk pada setiap kumpulan teks yang sistematis, dewasa ini korpus biasanya digunakan dalam arti sempit dan sering hanya digunakan untuk merujuk pada kumpulan teks sistematis yang telah terkomputerisasi atau yang disajikan dalam bentuk elektronik.
Masa awal penyusunan korpus
Penggunaan korpus dalam penelitian bahasa termasuk pendekatan yang cukup baru. Linguistik korpus muncul pada era 1960-an, bersamaan ketika Noam Chomsky memberi dampak yang besar terhadap kajian bahasa modern. Bukunya yang berjudul Syntactic Structures muncul pada tahun 1957 dengan cepat menjadi teks yang banyak dibahas. Buku kedua, Aspects of Theory of Syntax yang terbit pada 1965 memicu revisi standar paradigma dalam linguistik teoretis. Namun, ketika teori bahasa menjadi semakin berfokus pada bahasa sebagai fenomena universal, ahli bahasa lain semakin tidak puas dengan deskripsi yang mereka temukan untuk berbagai bahasa mereka kaji. Beberapa aturan tata bahasa dalam deskripsi tersebut tidak selaras dalam teks-teks tertulis. Oleh karena itu, data bahasa alami diperlukan.
Pada akhir 1950-an Randolph Quirk melakukan pengumpulan data bahasa (Survey of English Usage) untuk penelitian tata bahasa secara empiris. Awalnya data yang diperoleh tidak terkomputerisasi dan baru pada pertengahan 1980-an dilakukan oleh Quirk dan Greenbaum. Proyek itu dikenal dengan International Corpus of English (ICE). Data korpus terdiri atas 1 juta kata yang meliputi data lisan (500 ribu kata) dan tulis (500 ribu kata).
Proyek korpus kedua dilakukan pada 1960-an, yaitu Brown Corpus, diambil dari Brown University di Providence, Rhode Island. Korpus yang disusun oleh Nelson Francis dan Henry Ku?era ini terdiri atas 1 juta kata. Sampelnya 2 ribu kata diambil dari 500 teks Amerika yang meliputi 15 kategori teks seperti yang terdapat dalam Library of Congress, perpustakaan nasional Amerika. Brown Corpus disusun dengan cermat dan sangat mudah digunakan, dan sudah melalui proses baca ulang (proofread) sehingga hampir tidak ada kesalahan.
Proyek korpus yang ketiga adalah English Lexical Studies, dimulai di Edinburgh pada 1963 dan diselesaikan di Birmingham. Proyek itu dipimpin oleh John Sinclair, orang yang pertama kali menggunakan korpus secara khusus untuk penelitian leksikal dan yang membawa konsep baru tentang kolokasi. Proyek itu berbasis sampel teks elektronik bahasa lisan dan tulis yang sangat kecil, tidak sampai satu juta kata.
Proyek korpus berikutnya dibuat untuk kepentingan penyusunan kamus, yaitu Collins Cobuild English Language Dictionary, yang disusun pada pertengahan 1970-an dan diterbitkan pada 1987 di bawah panduan John Sinclair. Itu adalah pertama kalinya kamus bahasa umum yang disusun berdasarkan korpus. Oleh karena itu, korpus tersebut harus cukup besar agar dapat memasukkan seluruh lema dan makna kata yang tercakup di dalamnya. Korpus tersebut terdiri atas 18,3 juta kata.
Selanjutnya, proyek korpus terus bermunculan, di antaranya London-Lund Corpus of Spoken English (500 ribu kata, lisan), British National Corpus (100 juta kata), Bank of English (455 juta kata), American National Corpus (14 juta kata), Corpus of Contemporary American English (450 juta kata), dan International Corpus of English (1 juta kata dari setiap variasi regional/nsional).
Tipologi korpus
Ada beberapa jenis korpus yang dapat digunakan untuk berbagai jenis analisis, di antaranya
- korpus umum/ korpus referensi (vs korpus khusus), misalnya British National Corpus (BNC) atau Bank of English, menggambarkan suatu bahasa atau variasi bahasa secara keseluruhan (bahasa lisan dan tulis, jenis teks yang berbeda, dsb.);
- korpus historis (vs korpus kontemporer), misalnya A Representative Corpus of Historical English Registers (ARCHER), menggambarkan tahap tahap-tahap awal suatu bahasa;
- korpus regional (vs korpus yang berisi lebih dari satu variasi), misalnya Wellington Corpus of Written New Zealand English (WCNZE), menggambarkan satu variasi regional suatu bahasa;
- korpus pemelajar (vs korpus penutur jati), misalnya International Corpus of Learner English, menggambarkan bahasa yang digunakan oleh para pemelajar suatu bahasa;
- korpus multibahasa (vs korpus ekabahasa), menggambarkan dua atau lebih bahasa yang berbeda dengan teks yang sama (untuk analisis kontrastif); dan
- korpus lisan (vs korpus tulis vs korpus campuran), misalnya London-Lund Corpus of Spoken English, menggambarkan bahasa lisan.
Ada juga pembedaan jenis korpus dengan tidak merujuk pada teks-teks yang telah dimasukkan ke dalam korpus, tetapi merujuk pada bagaimana teks-teks itu diperlakukan. Jenis korpus itu adalah
- korpus teranotasi (vs korpus ortografis), di dalamnya beberapa jenis analisis linguistik telah dilakukan pada teks, seperti analisis kalimat dan klasifikasi kelas kata.
Peran korpus dalam penyusunan kamus
Dalam penyusunan kamus, korpus sangat membantu dalam mengerjakan mikrostruktur kamus yang meliputi lema/sublema, kelas kata, definisi, dan penulisan contoh pemakaian. Pekamus menggunakan program komputer untuk mengekstrak informasi dari korpus bahasa. Berikut ini adalah hal yang dapat dilakukan korpus dalam penyusunan kamus.
- Pada tahap pengumpulan lema, korpus dapat membantu pekamus dalam menyusun senarai kata mulai dari frekuensi yang tertinggi hingga frekuensi yang terendah. Pekamus dapat memilih berapa kata yang akan ia masukkan ke dalam kamus sesuai dengan jenis kamus yang akan disusun berdasarkan frekuensi kemunculannya. Gambar 1 adalah korpus yang diekstrak dengan menggunakan sketch engine. Dapat dilihat dalam tabel itu bahwa kata yang, dan, dan di adalah tiga kata dengan frekuensi kemunculan tertinggi di atas 1 juta kali.
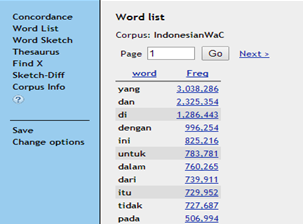
Gambar 1: Senarai kata
- Pada tahap penentuan lema, korpus—dengan program konkordansi—dapat membantu pekamus untuk membedakan mana lema/sublema yang berupa kata majemuk atau idiom dan mana yang bukan. Dari data korpus pada Gambar 2 terlihat ada 5 frasa kata benda, yaitu rumah tangga, rumah sakit, rumah kayu, rumah sendiri, dan rumah Tuhan. Dua di antaranya tidak termasuk kata majemuk, yaitu rumah kayu dan rumah sendiri. Oleh karena itu, keduanya tidak dapat dimasukkan dalam kamus sebagai lema/sublema.
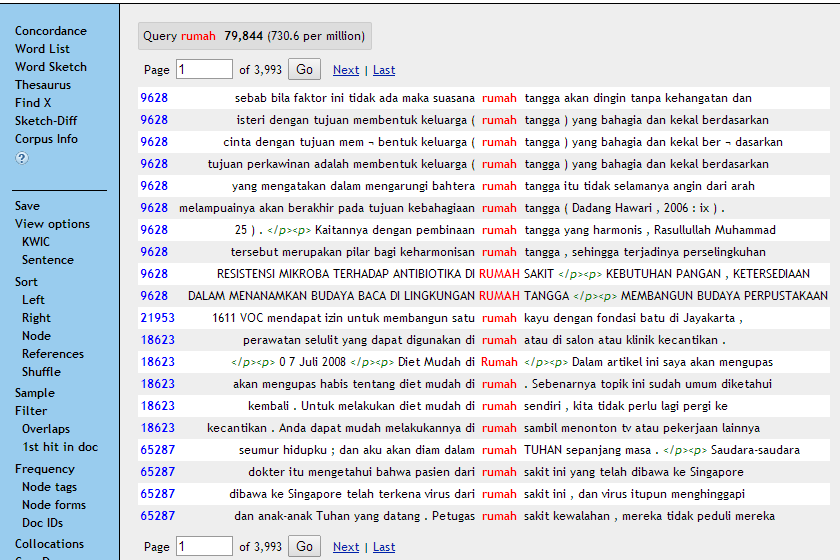
Gambar 2: Konkordansi kata rumah
- Korpus dapat membantu dalam hal penentuan kelas kata sebuah lema karena korpus memberikan konteks yang berbeda-beda tempat kata itu berada. Contohnya, kata salut dalam KBBI Edisi IV (2008: 1211) hanya memiliki satu kelas kata, yakni nomina. Namun, ketika kata salut diekstrak dari korpus, didapati bahwa ternyata kata salut juga dapat memiliki kelas kata adjektif, seperti pada kalimat 56279, 19125, dan 4172 dalam Gambar 3.
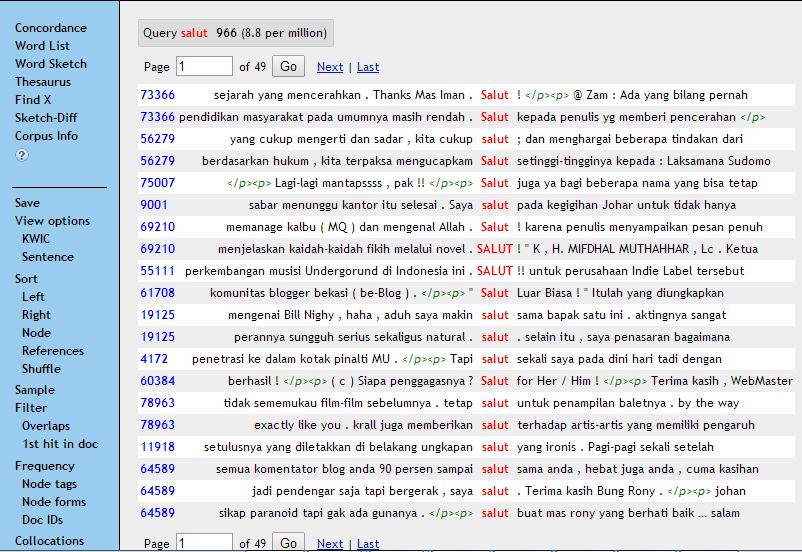
Gambar 3: Konkordansi kata salut
- Korpus membantu pekamus dalam mendefinisikan suatu lema. Proses pendefinisian biasanya memerlukan beberapa tahap analisis hingga dapat dihasilkan definisi yang baik dan tepat. Berdasarkan data yang tersedia, sublema mengentri dapat diberi definisi ‘memasukkan data, informasi, dsb. ke suatu tempat’.
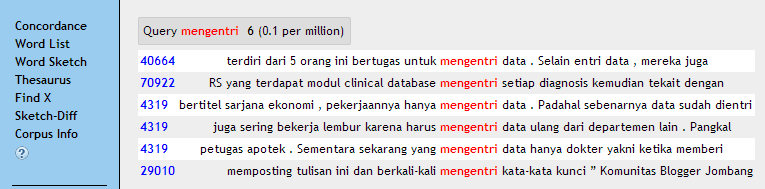
Gambar 4: konkordansi kata mengentri
- Korpus memberikan keleluasaan kepada pekamus dalam mencari dan menentukan contoh yang baik bagi pengguna kamus. Pengguna kamus, setelah mencari makna suatu kata, biasanya meneruskan dengam melihat contoh kalimat. Contoh yang baik adalah contoh yang menunjukkan bagaimana kata dipakai dalam konteks dan membantu untuk menjelaskan apa arti kata tersebut. Contoh untuk sebuah kata/lema dalam kamus harus sama dengan ketika kata tersebut digunakan dalam kehidupan nyata.
- Korpus membantu dalam mengidentifikasi kolokasi sebuah kata. Seperti yang terlihat pada Gambar 5, kata makan dapat berkolokasi dengan kata minum, siang, makan, malam, makanan, dan seterusnya.
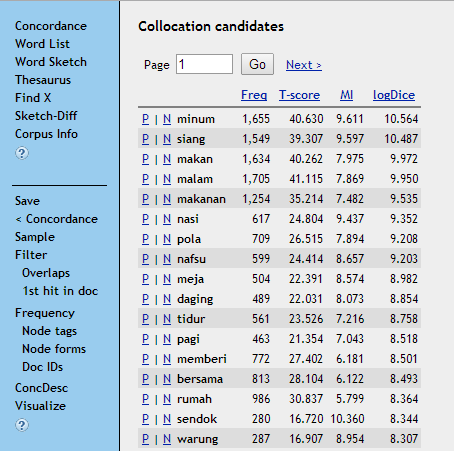
Gambar 5: Kolokasi kata makan
- Korpus dapat membantu melacak perubahan kata. Kata-kata baru adalah manifestasi paling jelas dari perubahan bahasa. Korpus dapat membantu mencari perubahan yang lebih halus dalam bahasa, misalnya makna baru dari kata-kata yang ada atau perubahan ejaan atau bahkan perubahan tata bahasa.
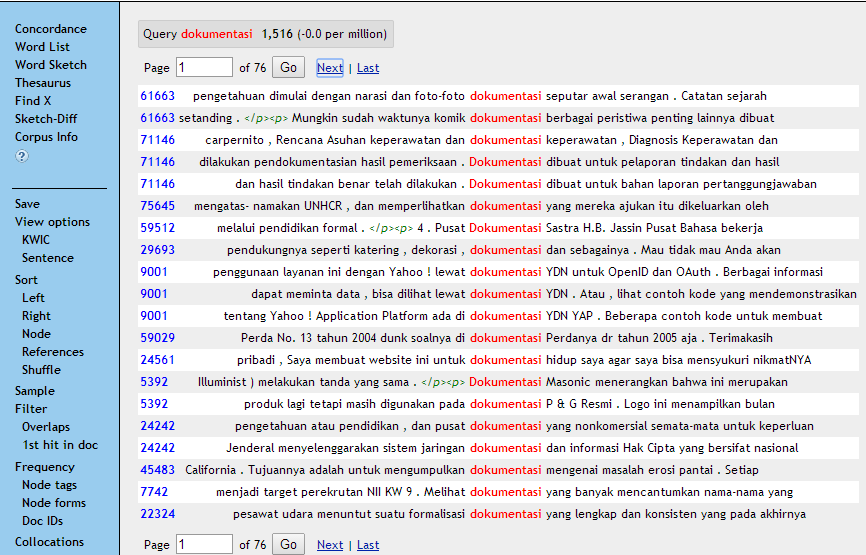
Gambar 6: Konkordansi kata dokumentasi
Lema dokumentasi dalam KBBI Edisi IV (2008: 338) memiliki dua polisem, yaitu 1 pengumpulan, pemilihan, pengolahan, dan penyimpanan informasi dalam bidang pengetahuan; 2 pemberian atau pengumpulan bukti dan keterangan (seperti gambar, kutipan, guntingan koran, dan bahan referensi lain): panitia dilengkapi dengan seksi pameran, publikasi, dan dokumentasi. Jika data korpus pada Gambar 6 diamati dengan teliti, tampak bahwa makna dokumentasi juga dapat berarti ‘dokumen yang disediakan atau dikumpulkan sebagai bukti atau bahan referensi’. Jadi, lema dokumentasi dapat dikatakan telah mengalami perubahan bahasa, khususnya pada makna.
Penutup
Penggunaan korpus dalam dunia perkamusan masih dalam masa pertumbuhan. Penggunaan korpus pun telah menjadi standar dalam penyusunan kamus yang modern. Hal itu juga didukung oleh perkembangan teknologi komputer yang mampu mengolah korpus sedemikian rupa sehingga pekamus dimudahkan dalam pekerjaannya. Temuan-temuan baru pun banyak diperoleh melalui analisis data korpus secara sistematis. Hal itu berdampak pada pembaruan dan perbaikan entri kamus sehingga menghasilkan deskripsi yang seakurat mungkin dari suatu bahasa.
Daftar Pustaka
Halliday, M.A.K, Wolfgang Teubert, Collin Yallop, dan Anna Cermakova. 2004. Lexicology and Corpus Linguistics: An Introduction. London: Continuum.
Hunston, Susan, Sara Laviosa, dan Nicholas Groom. n/a. “Corpus Linguistics”. Birmingham: The Centre for English Language Studies, University of Birmingham.
Kushartanti, Untung Yuwono, dan Multamia RMT Lauder. 2007. Pesona Bahasa: Langkah Awal Memahami Linguistik. Jakarta: Gramedia Pustaka Utama.
Teubert, Wolfgang and Ramesh Krishnamurthy. Corpus Linguistics: Critical Concepts in Linguistics. London: Routledge.
Tim Redaksi KBBI. 2008. Kamus Besar Bahasa Indonesia Edisi Keempat. Jakarta: Gramedia Pustaka Utama.
http://www.americannationalcorpus.org/OANC/index.html. Diakses 3 Agustus 2014.
http://www.as.uni-heidelberg.de/personen/Nesselhauf/files/Corpus Linguistics Practical Introduction.pdf. Diakses pada 13 Juli 2014.
http://corpus.byu.edu/coca/compare-boe.asp. Diakses 3 Agustus 2014.
http://corpus.byu.edu/coca/compare-bnc.asp. Diakses 3 Agustus 2014.
http://www.macmillandictionaries.com/features/from-corpus-to-dictionary/. Diakses 14 Juli 2014
http://www.oxforddictionaries.com/words/about-the-oxford-english-corpus. Diakses 14 Juli 2014
http://www.oxforddictionaries.com/words/the-corpus-and-the-dictionary-entry. Diakses 14 Juli 2014
https://the.sketchengine.co.uk/auth/corpora/. Diakses 14 Juli 2014.
http://www.ucl.ac.uk/english-usage/projects/ice.htm. Diakses 3 Agustus 2014.

Adi Budiwiyanto
...
Sedang Tren
-
 Bahasa Indonesia Men...
22 Januari 2022
Bahasa Indonesia Men...
22 Januari 2022
-
Legenda Asal-Usul Te...
22 Januari 2022
-
Bahasa dan Nasionali...
22 Januari 2022
-
Rudapaksa...
18 Januari 2022
-
Menumbuhkan Gerakan ...
17 Januari 2022